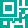
5月26日凌晨,全球权威三方编程榜单Code Arena放榜,阿里最新旗舰模型Qwen3.7-Max得分1541,超越GPT-5.5、Gemini-3.5-Flash、GLM-5.1、Kimi-K2.6等一众模型,仅次于Claude系列,在大模型厂商中排名全球第二,这也标志着在代码理解与生成领域,千问3.7成功跻身全球编程模型第一梯队。

Code Arena榜单显示,凭借Qwen3.7-Max,阿里位列全球第二
编程能力是当下模型智能水平的核心指标,而Code Arena是由知名第三方大模型盲测平台LMArena推出的最具影响力的榜单之一。与传统的代码基准测试不同,Code Arena并不考核孤立的代码片段生成或传统算法题,而是由开发者出题,要求模型从零生成完整的、可交互的Web应用程序,并交由用户对匿名模型的生成效果进行两两PK,由投票综合生成榜单,因此Code Arena也被认为是目前全球最具公信力的AI编程能力评测之一。经全球开发者以真实使用体验盲测投票,千问3.7模型编程能力位居前4,打破由Claude-Opus-4.7和4.6统治已久的前四格局,Qwen3.7-Max也成为目前榜单中唯一突破1540分大关的国产大模型。
据了解,面向Agent打造的Qwen3.7-Max在编程、智能体、长程任务等核心能力上实现了大幅突破,不但能在数小时内独立完成专业团队耗时2周的复杂项目端到端交付,大幅提升办公自动化和企业级生产力,甚至可以持续运行35小时、累计超1000次工具调用的复杂长程任务,自我编程优化芯片内核。
Qwen3.7-Max发布后迅速在全球引发强烈反响。大量独立开发者、AI创作者、企业用户第一时间在社交媒体上分享了测评结果:多位开发者评价其”长程自主执行能力令人印象深刻””是真正能把事情做完的智能体基座模型”;有AI机构在相同提示词下同步横评了Qwen3.7-Max、Claude-4.7与GPT-5.5,发现千问3.7较上代的性能提升幅度最大、推理成本最低,在输出速度和生成质量两个维度上相较其他模型均有明显优势。
 mingzhiLatest posts by mingzhi (see all)
mingzhiLatest posts by mingzhi (see all)